1.本发明涉及含硫有机废水处理领域,具体涉及一种厌氧消化中硫化氢产生量的智能预测方法。
背景技术:
2.厌氧消化广泛应于处理有机废水中有机物的方法。甲烷是一种高能量的可再生能源,是使用厌氧消化处理有机物的终端产物。然而,来自许多行业的有机废水总是含有高浓度的硫酸盐。硫酸盐会在厌氧消化的过程中生成对产甲烷菌具有毒性的硫化氢,最终抑制甲烷的产量。因此,预测硫化氢产生量能评价厌氧消化性能并进一步采取合理措施以减少硫化氢的生成。
3.动力学模型是一种通过考虑内部机制对厌氧消化过程进行模拟,并对硫化氢的产生量进行预测的方法。厌氧消化过程中的硫化氢的产生受多个因素影响并且各个影响因素之间存在相互作用。例如,cod/so
42
–
、vfas、ph都会对硫化氢的生成产生影响,当cod/so
42
–
在5到1.5的范围降低,ph下降时,硫化氢的产生量会不断的上升。而硫化氢产生量的提升导致vfas的不断积累,引起ph的下降,进一步的引起硫化氢产量的提升。由于厌氧反应过程中各个特征之间复杂的关系存在,采用动力学模型往往由于无法完全考虑到硫化氢产生的内部机制而导致使用该方法对硫化氢的产生量的预测无法达到目标精度。相比之下,人工神经网络是一种不必明确考虑内部机制便可对目标参数进行预测的人工智能技术,它已经被广泛适应来预测厌氧消化过程中的各个参数,并取得了良好的效果。然而,一方面,人工神经网络结构简单,无法发现厌氧消化过程中变量之间更深层的关系从而导致预测精度的降低;另一方面,人工神经网络往往需要大量的数据对其进行训练以保证一定的预测精度,由于厌氧消化是一个缓慢且复杂的生化过程,收集其中的大量数据需消耗大量的时间和成本。因此,迫切的需要一种方法能够获得大量的数据对结构更复杂的模型进行训练并保证硫化氢产生量的预测精度。
技术实现要素:
4.针对少量数据训练的人工神经网络模型无法对厌氧消化过程中硫化氢产生量进行高精度的预测的问题,本发明提供了一种厌氧消化中硫化氢产生量的智能预测方法,该方法基于数据虚拟扩充和深度神经网络进行的预测,预测过程简单,且精度高。
5.为解决上述技术问题,本发明采取的技术方案为:
6.一种厌氧消化中硫化氢产生量的智能预测方法,包括以下步骤:
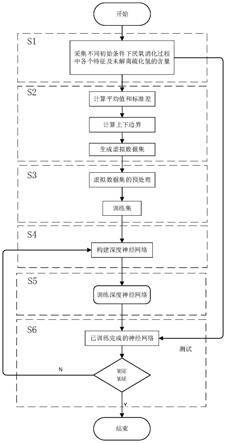
7.s1:采集在不同初始条件下厌氧消化反应过程中污水的各个特征的含量和硫化氢产生量分别作为深度神经网络的输入和输出变量,所有收集的数据作为原始数据集和测试集,共采集m次;各个特征的含量为硫化氢产生量数据集为
整合原始数据为测试集其中k为对废水中进行数据采集的各特征的数量,m为实验过程中采集的次数,为第k个特征在第m次采集到的值,h
m
为第m次采集到的硫化氢产生量;
8.s2:对收集的原始数据集采用虚拟扩充方法生成虚拟数据集;
9.s3:对虚拟数据集进行预处理,即可得到预处理后的虚拟数据集,并将其作为深度神经网络的训练集;
10.s4:建立深度神经网络由输入层、隐藏层、输出层组成,对深度神经网络的隐藏层的层数和隐藏层神经元的数量进行设计,对深度神经网络的激活函数和学习函数进行选择;
11.s5:利用训练集即虚拟数据集对深度神经网络进行迭代训练得到训练后的深度神经网络;
12.s6:采用测试集对模型进行测试并根据评估函数进行模型优劣的评估,若满足对硫化氢产成量的预测精度要求,模型训练成功,若未满足,返回s4。
13.作为改进的是,步骤s1中所述特征为so
42
‑
浓度、cod、bod5、toc、ph、ch4产量或vfas含量一种或多种。
14.作为改进的是,步骤s2中对收集的原始数据集采用虚拟扩充方法生成虚拟数据集,具体步骤如下:
15.步骤1,计算各个特征的平均值μ
k
和标准差σ
k
[0016][0017][0018]
式中,是第k个特征中的第i个原始数据,μ
k
是第k个特征的平均值,σ
k
是第k个的特征的标准偏差;
[0019]
步骤2,计算虚拟数据生成的上边界和下边界
[0020]
上边界:lb=μ
k
+σ
k
[0021]
下边界:lb=μ
k
‑
σ
k
[0022]
步骤3,生成虚拟数据集
[0023]
对第i次采集的数据每次生成的虚拟数据集为循环z次共生成z组虚拟数据集为对每一次采集
的数据均生成虚拟数据集得到所有的虚拟数据集为其中代表第i次采集数据的第k个特征在第c次生成的虚拟数据。
[0024]
作为改进的是,步骤s3中采用公式:对产生的虚拟数据集进行归一化得到数据集其中v
kmax
为虚拟数据集中第k个特征的最大值,v
kmin
为虚拟数据集中第k个特征的最小值。
[0025]
作为改进的是,步骤s4的具体步骤如下:
[0026]
步骤i,对隐藏层的层数及每一层神经元的数量进行设计以确定深度神经网络的结构,输入层的的神经元的个数与在不同初始条件下厌氧消化反应过程中污水采集的各个特征的数量相同,输出层的神经元为硫化氢产生量;
[0027]
步骤ii,对输入层、隐藏层、输出层之间的超参数权重(w)、偏差(b)、学习率(η)进行初始化设置;对隐藏层神经元和输出层神经元选择合适激活函数;
[0028]
步骤iii,选择合适的训练算法在神经网络的训练过程中进行迭代训练。
[0029]
进一步改进的是,步骤ii中所述激活函数为relu,sigmoid,tanh或linear。
[0030]
进一步改进的是,步骤iii中所述的训练算法为gradient descent backpropagation或levenberg
‑
marquardt backpropagation。
[0031]
作为改进的是,步骤s6的具体评估如下:使用s3获得的训练集对s5建立的深度神经网络进行训练,训练完成后使用s1获得的测试集对训练完的深度神经网络进行测试,根据验证函数评判深度神经网络的预测精度要求,若达不到要求,返回s4,迭代直至深度神经网络满足预测精度要求。
[0032]
进一步改进的是,所述验证函数为mse,mae或mape中一种。
附图说明
[0033]
图1为本发明预测方法的系统流程图;
[0034]
图2为本发明步骤s4中建立的深度神经网络的结构图。
具体实施方式
[0035]
如图1所示,一种厌氧消化中硫化氢产生量的智能预测方法,包括以下步骤:
[0036]
s1:采集在初始cod/so
42
–
分别为1、2、3情况下,初始ph分别为7、7.5、8时,在厌氧消化反应的过程中so
42
‑
浓度、cod、bod5、toc、ph、ch4、vfas这7个特征的含量,采集时间为每6小时一次,每组反应共采集7次,可获取63组数据。七个特征含量的数据集硫
化氢产生量的数据集为整合原始数据集为测试集
[0037]
s2:对收集的原始数据集采用虚拟扩充方法生成虚拟数据集;
[0038]
(1)计算各个特征的平均值μ
k
和标准差σ
k
[0039][0040][0041]
式中,是第k个特征中的第i个原始数据,μ
k
是第k个特征的平均值,σ
k
是第k个的特征的标准偏差。
[0042]
(2)计算虚拟数据生成的上下边界
[0043]
上边界:lb=μ
k
+σ
k
[0044]
下边界:lb=μ
k
‑
σ
k
[0045]
(3)生成虚拟数据集
[0046]
对第i次采集的数据每次生成的虚拟数据集为循环z次共生成z组虚拟数据集为对每一次采集的数据均生成虚拟数据集得到所有的虚拟数据集为其中代表第i次采集数据的第k个特征在第c次生成的虚拟数据。在本例中循环4次,共生成252组数据。
[0047]
s3:对虚拟数据集进行预处理。
[0048]
对虚拟数据集进行预处理,并将预处理后的虚拟数据集作为深度神经网络的训练集;采用公式:对产生的虚拟数据集进行归一化得到数据集其中v
kmax
为虚拟数据集中第k个特征的最大值,v
kmin
为虚拟数据集中第k个特征的最小值。本专利中选择的预处理方法以此为例但不限于此,其他相关方法为本专利的扩充,而不应该被理解为对本专利的限制条件。
[0049]
s4:深度神经网络由输入层、隐藏层、输出层组成,如图2所示。对深度神经网络的隐藏层的层数和隐藏层神经元的数量进行设计,对深度神经网络的激活函数和学习函数进行选择。
[0050]
(1)对隐藏层的层数及每一层神经元的数量进行设计以确定深度神经网络的结构,输入层的的神经元的个数与在不同初始条件下厌氧消化反应过程中污水采集的各个特
征的数量相同,输出层的神经元为硫化氢产生量;
[0051]
(2)对输入层、隐藏层、输出层之间的超参数权重(w)、偏差(b)、学习率(η)进行初始化设置,初始化w为0.2,b为0,η为0.05;对隐藏层神经元和输出层神经元选择合适激活函数,隐藏层的传递函数选择为sigmoid函数,输出层选择liner函数。
[0052]
(3)选择合适的训练算法在神经网络的训练过程中进行迭代训练。本示例中选择adam函数作为训练算法。
[0053]
s5:利用训练集即虚拟数据集对深度神经网络进行迭代训练得到训练后的深度神经网络;
[0054]
s6:采用测试集对模型进行测试并根据评估函数进行模型优劣的评估。
[0055]
使用s3获得的训练集对s5建立的深度神经网络进行训练,训练完成后使用s1获得的测试集对训练完的深度神经网络进行测试,根据评价函数评判深度神经网络的预测精度要求,若达不到要求,返回s4,迭代直至深度神经网络满足预测精度要求。选择均方误差mse、平均绝对误差mae作为评价函数,其中mse和mae越小预测精度越高。
[0056]
所述的均方误差具体计算公式为:
[0057][0058]
所述的平均绝对误差具体计算公式为:
[0059][0060]
其中为深度神经网络的预测值,h
i
为未解离硫化氢的真实值。
[0061]
通过使用原始数据和虚拟扩充数据分别对anns和深度神经网络进行训练,经过迭代,最终确定最佳的深度神经网络结构为隐藏层为两层,每一层神经元的数量为100个。使用原始数据训练的anns的最佳评估结果mae为23.18,mse为464.02,使用虚拟扩充数据训练具有2层隐藏层每层具有100个神经元的深度神经网络的mae为7.62,mse为73.58。通过对比,采用虚拟数据集训练的深度神经网络具有更高的预测精度。
[0062]
以上所述,仅为本发明较佳的具体实施方式,本发明的保护范围不限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可显而易见地得到的技术方案的简单变化或等效替换均落入本发明的保护范围内。
技术特征:
1.一种厌氧消化中硫化氢产生量的智能预测方法,其特征在于,包括以下步骤:s1:采集在不同初始条件下厌氧消化反应过程中污水的各个特征的含量和硫化氢产生量分别作为深度神经网络的输入和输出变量,所有收集的数据作为原始数据集和测试集,共采集m次;各个特征的含量为硫化氢产生量数据集为整合原始数据为测试集其中k为对废水中进行数据采集的各特征的数量,m为实验过程中采集的次数,为第k个特征在第m次采集到的值,h
m
为第m次采集到的硫化氢产生量;s2:对收集的原始数据集采用虚拟扩充方法生成虚拟数据集;s3:对虚拟数据集进行预处理,即可得到预处理后的虚拟数据集,并将其作为深度神经网络的训练集;s4:建立深度神经网络由输入层、隐藏层、输出层组成,对深度神经网络的隐藏层的层数和隐藏层神经元的数量进行设计,对深度神经网络的激活函数和学习函数进行选择;s5:利用训练集即虚拟数据集对深度神经网络进行迭代训练得到训练后的深度神经网络;s6:采用测试集对模型进行测试并根据评估函数进行模型优劣的评估,若满足对硫化氢产成量的预测精度要求,模型训练成功,若未满足,返回s4。2.根据权利要求1所述的一种厌氧消化中硫化氢产生量的智能预测方法,其特征在于,步骤s1中所述特征为so
42
‑
浓度、cod、bod5、toc、ph、ch4产量或vfas含量一种或多种。3.根据权利要求1所述的一种厌氧消化中硫化氢产生量的智能预测方法,其特征在于,步骤s2中对收集的原始数据集采用虚拟扩充方法生成虚拟数据集,具体步骤如下:步骤1,计算各个特征的平均值μ
k
和标准差σ
kk
式中,是第k个特征中的第i个原始数据,μ
k
是第k个特征的平均值,σ
k
是第k个的特征的标准偏差;步骤2,计算虚拟数据生成的上边界和下边界上边界:lb=μ
k
+σ
k
下边界:lb=μ
k
‑
σ
k
步骤3,生成虚拟数据集对第i次采集的数据每次生成的虚拟数据集为
循环z次共生成z组虚拟数据集为对每一次采集的数据均生成虚拟数据集得到所有的虚拟数据集为其中,代表第i次采集数据的第k个特征在第c次生成的虚拟数据。4.根据权利要求1所述的一种厌氧消化中硫化氢产生量的智能预测方法,其特征在于,步骤s3中采用公式:对产生的虚拟数据集进行归一化得到数据集其中v
kmax
为虚拟数据集中第k个特征的最大值,v
kmin
为虚拟数据集中第k个特征的最小值。5.根据权利要求1所述的一种厌氧消化中硫化氢产生量的智能预测方法,其特征在于,步骤s4的具体步骤如下:步骤i,对隐藏层的层数及每一层神经元的数量进行设计以确定深度神经网络的结构,输入层的的神经元的个数与在不同初始条件下厌氧消化反应过程中污水采集的各个特征的数量相同,输出层的神经元为硫化氢产生量;步骤ii,对输入层、隐藏层、输出层之间的超参数权重(w)、偏差(b)、学习率(η)进行初始化设置;对隐藏层神经元和输出层神经元选择合适激活函数;步骤iii,选择合适的训练算法在神经网络的训练过程中进行迭代训练。6.根据权利要求5所述的一种厌氧消化中硫化氢产生量的智能预测方法,其特征在于,步骤ii中所述激活函数为relu,sigmoid,tanh或linear。7.根据权利要求5所述的一种厌氧消化中硫化氢产生量的智能预测方法,其特征在于,步骤iii中所述的训练算法为gradient descent backpropagation或levenberg
‑
marquardt backpropagation。8.根据权利要求1所述的一种厌氧消化中硫化氢产生量的智能预测方法,其特征在于,步骤s6的具体评估如下:使用s3获得的训练集对s5建立的深度神经网络进行训练,训练完成后使用s1获得的测试集对训练完的深度神经网络进行测试,根据验证函数评判深度神经网络的预测精度要求,若达不到要求,返回s4,迭代直至深度神经网络满足预测精度要求。9.根据权利要求8所述的一种厌氧消化中硫化氢产生量的智能预测方法,其特征在于,所述验证函数为mse,mae或mape中一种。
技术总结
本发明公开一种厌氧消化中硫化氢产生量的智能预测方法,采集厌氧消化过程中各个特征构成原始数据集;对原始数据集进行虚拟扩充生成虚拟数据集;接着构建深度神经网络并使用虚拟数据集其进行迭代训练得到最佳的预测模型。该种智能预测方法厌氧消化过程中的真实数据使用虚拟扩充方法获得大量可以模拟厌氧消化过程的虚拟数据并对深度神经网络进行训练,大大降低了数据采集时间和经费成本,在满足深度神经网络对大量数据需求的同时,还能满足对厌氧消化过程中硫化氢产生量预测的精度要求。氧消化过程中硫化氢产生量预测的精度要求。氧消化过程中硫化氢产生量预测的精度要求。
技术开发人、权利持有人:远野 殷万欣 乔椋 朱莎莎 陈天明 丁成 王爱杰

